

Sculpture by Finn Stone
Software Development Best Practices in 2016.
One of the touchstone differentiators of Axial Engineering is to constantly recognize that “Engineer is a subclass of HumanBeing”. As such, we are prone to act with implicit biases which might affect our effectiveness. Since another one of our principles is to maximize the impact of our work, we strive to constantly challenge our assumptions, especially about how our course of action relates to our highest goals as a company, as professionals and as Human Beings. One area that is ripe for re-assessment is the set of accepted ‘Best Practices’ in Software Development, and how they relate to our goals. In that spirit, we’ll be touching over this series of posts on several of the dogmas of our craft, and thinking through their applicability to our situation and point in time.
Part I: Object-Oriented Design and the Fetish of Reusability
Over the last couple of decades, Object-Oriented Design achieved the status of dogma in terms of what constitutes good quality in software development. That’s how “Object-Oriented” and “good” became almost synonymous in our craft. There is also, on the surface, plenty of agreement on what constitutes “Object Orientation” in software design. Almost every interviewee is able these days to recite the expected mantra: “Encapsulation, Inheritance, Polymorphism and Function Overloading”. …”You know, like Java, or Ruby or C++”.
We should all be concerned about unexamined assumptions, and there are a couple of huge ones in the common views of OOD, which in my opinion affect our whole industry considerably. The first one is on the definition of what constitutes good Object-Oriented Design and its relationship with these “Four Noble Truths” mentioned above, which we’ll touch upon in a future post. The second one is more implicit, hidden and perhaps more pernicious: It pertains to the reason on why we want Object Orientation in our software. Let’s start there, for there would be no profitable reason to invest time reasoning about the essence of a technique, if we can’t identify the benefits of using it.
It might sound strange to even ask what’s the benefit of Object-Oriented Design. Ask almost anyone and the same answer will be forthcoming: Reusability, of course! … Finally moving software construction into the Industrial Age, where we can buy or download standard parts, just like microchips and build good quality software in record time!… The best I understand it, the common perception of Reusability is to create software components as generic and flexible as possible, so that they can be applicable to the greatest number of unforeseen future uses while remaining unchanged. As the theory goes, if we build our software this way, we’ll be able to never touch these components again, and use them in many thereto unforeseen scenarios.
So far so good, I suppose. Alas, in order to build such extreme level of ‘genericity’ in our software, the complexity and cost of building it goes up almost exponentially. Let’s dwell on that for a moment: Suppose you work for a company that sells some gadgets called ‘Things’. Let’s say you want to build some software, like your “Inventory Manager of ‘Things’” where ‘Thing’ is a well-defined concept that everyone in your company understands. But let’s, as a thought experiment, make this software as reusable as possible. To achieve this, typically, we’d start with classes, then we’d make them into class hierarchies using Inheritance, and then we’d abstract the interfaces into protocols, contracts or interfaces, depending on your language of choice. But… wait! Who knows if we’ll need to apply this to some future ‘OtherTypeOfThing’? So, let’s make some ‘AbstractThing and ‘SpecialThing’ and their corresponding ‘IAbstractThing’ and ‘ISpecialThing’ abstract interfaces, while considering every combination of concepts or ideas in which such a hierarchy could be remotely applicable. Done? Not so fast: At that point we might want to throw in our ‘AbstractThingFactory’ and several ‘ConcreteThingFactories’, (after all, we want to throw in some Design Patterns), and while we are at it, we might as well make ‘Thing’ generic, with all the ‘AbstractThing<T>’, ‘Thing<T>’ and even ‘ThingHelper<T>’ paraphernalia that it will ever require. And, -bonus!-, as a software developer, it is likely that you love dealing with abstraction, so most likely you’ll have a blast thinking through this. Life as a reusable software developer feels at this point like it it can’t get any better. Throw in some Inversion-of-Control and Configuration-by-Convention, while controlling all of these options with a nice, juicy (but computationally unaccountable) set of XML or JSON configuration files, and you’ll be seemingly well on your way to the Holy Grail of Reusability.
Dizzy yet? Let’s go back to Earth. Shall we?
The return on every investment is the relationship between the cost or effort put into it and the real benefits it gives you over time. First, on the effort: The more parts something has, the more it is, by definition, complex. And complexity is always costly: It costs more to build it and it costs more to maintain it. In most cases, it also creates barriers of to diagnosing problems efficiently. For a very simple example, think about the added difficulty of debugging software that goes through abstract interfaces and injected components. Finally, the added complexity creates many different points of touch when a change is needed. Think of how you cursed your luck when you had to change an abstract interface that had many different concrete implementations. And I doubt your QA engineer liked you any more after that…You get the picture: Add up the hours of added effort required to keep such software operating well over its (shorter than you think) lifespan, and you’ll get a good idea of the cost incurred.
Let’s think, on the other hand, about the return side. Don’t get me wrong: Abstract Interfaces, Inversion of Control and Generic Containers or Algorithms all have use cases in which they provide many measurable benefits. We’ll even be discussing some interesting ones in a future post. But more often than not, the kinds of software for which Reusability is at the top of the priority stack are associated with frameworks that are intended from the beginning for an industry as a whole, and created at a great cost in order to save time in implementing concepts that are by definition abstract. They are also used by hundreds of unrelated teams, in unrelated domains. Think STL, or NumPy or the Java Collections framework. However, these are projects that operate in domains that are orthogonal to the problems most developers face day-to-day. This article from 1998 gives us a very interesting rule of thumb: “…You can’t call something reusable unless it’s been reused at least three times on three separate projects by three separate teams.”.
On narrower domains, if we examine the track record of our previous efforts, we’ll come to confront a disquieting reality: Most “reusable” software is actually never reused. And even when we account for the time saved for the cases when we do reuse it, for most domains we’ll come to see that the return-on-investment of building all software components as highly reusable is, by and large, negative. And yet we persist, as an industry, in perpetuating this myth, while ignoring other potential benefits that we can target in our development process.
And so, we arrive to the point where, if Reusability is the main benefit of Object-Oriented Design, from the cost/benefit point-of-view we might as well dispense with it, unless we are creating the next framework-level collections library. Otherwise, we are not likely to enjoy the benefits of the increased complexity. However, it is our contention that Object-Oriented Design does provide some other real, measurable benefits to the quality of software design, and that these benefits can be achieved without the exponential growth in complexity discussed above. But in order to discuss these benefits lucidly, we need to reexamine our notions of what is essential vs accidental in Object-Oriented Design Practices. That will be the subject of our next blog. For more on that, watch this space.
References
- SOA and the Reality of Reuse
- The Elusive Search for Business Frameworks
- Software Reusability: Myth Or Reality?
- The Reality of Object Reuse
- A Comparison of Software Reuse Support in Object-Oriented Methodologies
- Software Reuse: Principles, Patterns, Prospects



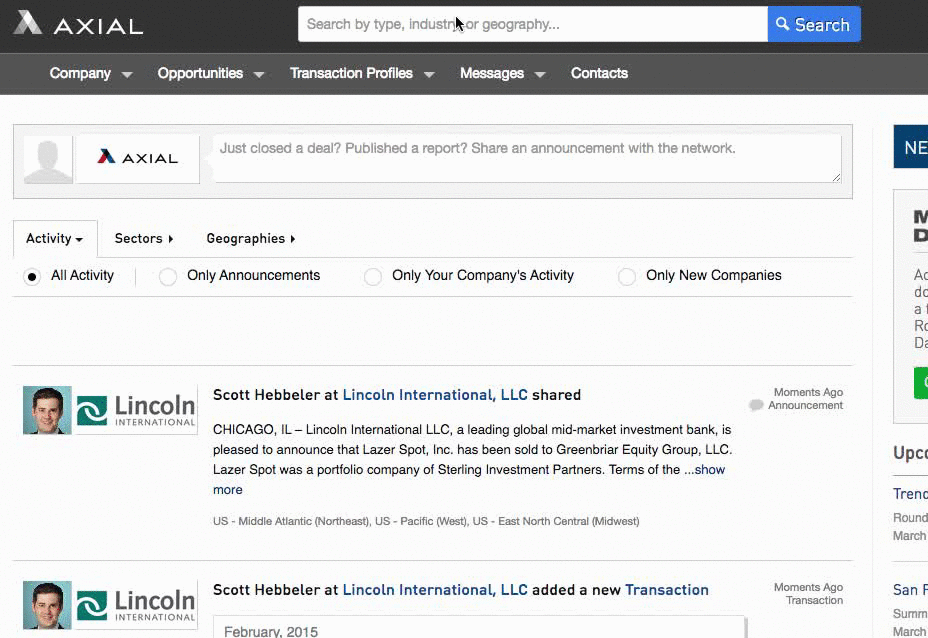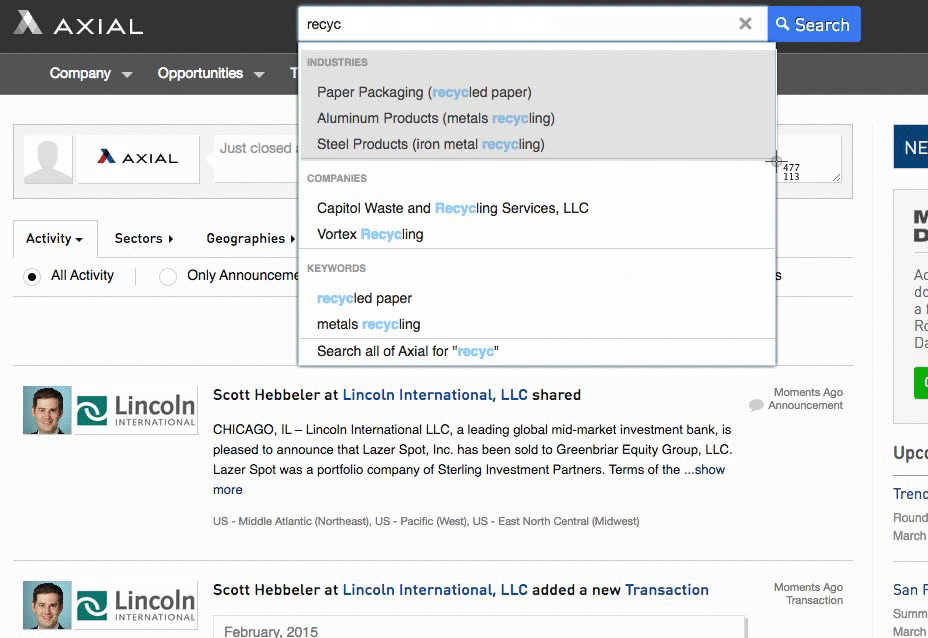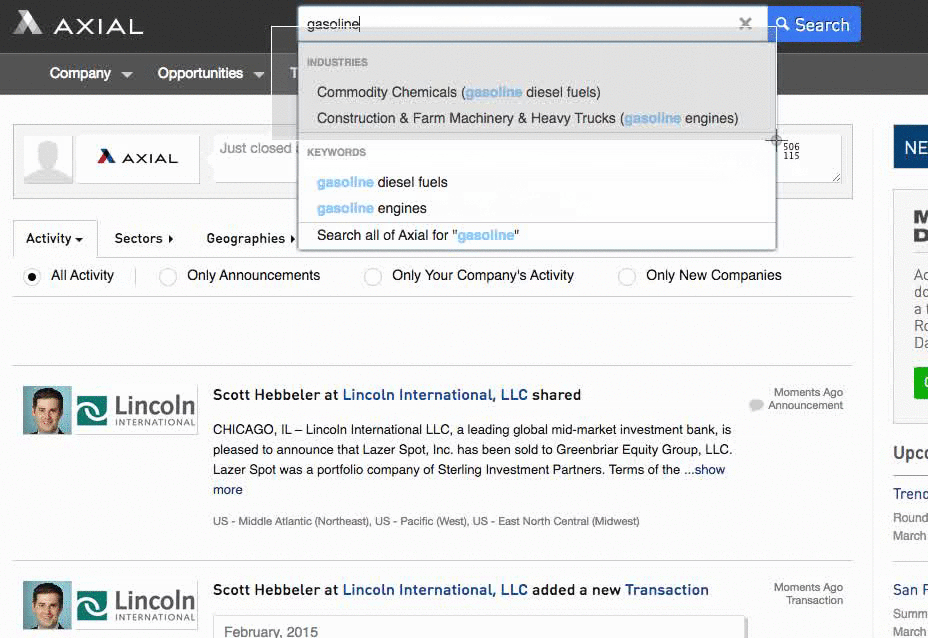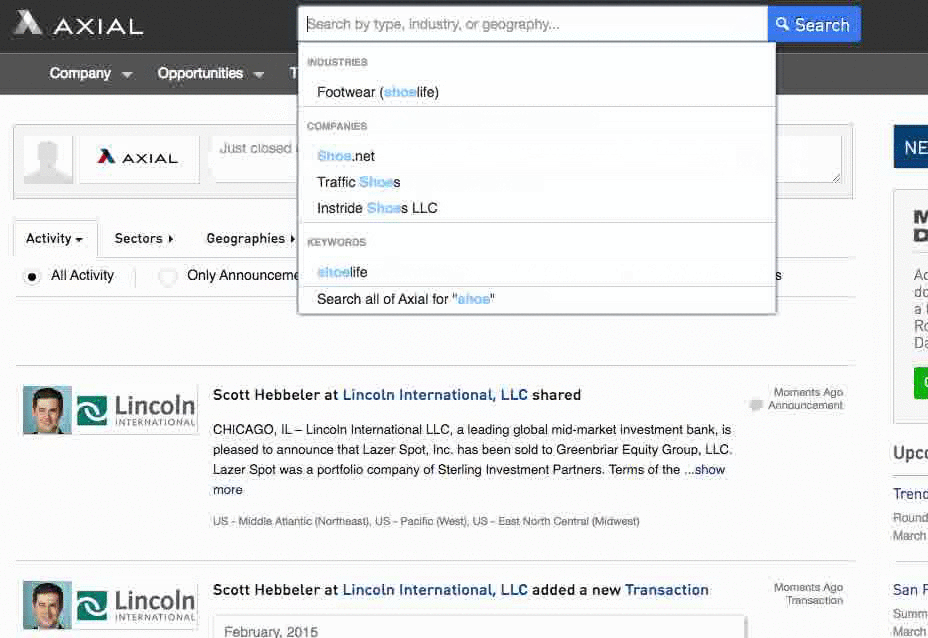
 “Being the first to respond to a deal on Axial gives you a 19% greater chance to closing it.” –
“Being the first to respond to a deal on Axial gives you a 19% greater chance to closing it.” – 


















 distances (
distances ( ,
,  , Chebyshev), cosine, correlation, span-norm, Bhattacharyya, Hellinger and Jensen Shannon Divergence. Based on some experimentation, we decided to use Jensen Shannon Divergence(JSD) to measure the distance between documents.
, Chebyshev), cosine, correlation, span-norm, Bhattacharyya, Hellinger and Jensen Shannon Divergence. Based on some experimentation, we decided to use Jensen Shannon Divergence(JSD) to measure the distance between documents.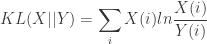 . This is a nice way to measure the difference between a probability distribution comparing to
. This is a nice way to measure the difference between a probability distribution comparing to 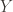 which is a reference distribution. One way to reason about this distance metric is to assume two probability distributions are exactly the same. Then,
which is a reference distribution. One way to reason about this distance metric is to assume two probability distributions are exactly the same. Then,  would be zero. They are exactly same, so the distance is 0. Why
would be zero. They are exactly same, so the distance is 0. Why 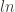 , you may ask and that is related to information theory. KL Divergence is also called relative entropy, so one could think the KL divergence as how much information is gained from
, you may ask and that is related to information theory. KL Divergence is also called relative entropy, so one could think the KL divergence as how much information is gained from 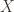 assuming that
assuming that 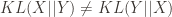 and that is a big problem as we cannot create a proper measure of between two observations without considering which is the reference and which one is the one that we measure the distance between the reference vector. In order to prevent this issue, there is a Symmetrised version(well sort of) which just sums up two different KL divergence between each other(
and that is a big problem as we cannot create a proper measure of between two observations without considering which is the reference and which one is the one that we measure the distance between the reference vector. In order to prevent this issue, there is a Symmetrised version(well sort of) which just sums up two different KL divergence between each other( in order to reach a symmetrised version of KL Divergence, but we have another way to measure the distance as well, which is most probably obvious at this point.
in order to reach a symmetrised version of KL Divergence, but we have another way to measure the distance as well, which is most probably obvious at this point.
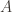 :
: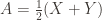
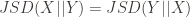


{kind=link}